
Episode 4: The Parliamentary Function
So far, I have released 3 episodes of the election blog series. As a reminder, the series is to get data on Ghanaian Presidential & Pariamentary results since 1992 till the latest: 2016 elections.
This was supposed to Episode 4: The 1996 Parliamentary Results. But guess what? Your girl got some better news. This episode will be the end of the Parliamentary section of the series.Your girl has got all the Parliamentary results from 1996 to 2016 and by the end of this post, you will as well, I will show you how.
TL;DR
The function dframe_MPResults takes 2 arguments: a Wikipedia URL and the position number of a table. The Wikipedia URL is a page with the data we want (Parliamentary Results).These are the links for 1996, 2000, 2004, 2008, 2012 & 2016 parliamentary election results on Wikipedia.
The second argument is the position of the table which contains the parliamentary results. All the election years have their results stored in the Second (2) table The only exception is the 2012 elections whose data is in the Third (3) table.
The output of the function is a dataframe with 6 columns in the following order:
- Constituency
- Elected MP
- Elected Party
- Previous MP
- Previous Party
- Region
##### Load required libraries
library(rvest)
library(dplyr)
library(stringr)
#################################### FXN 1 #######################
fxn_getURL <- function(wiki_URL, tableNum){
# get data and convert into table
html_Parliament <- read_html(wiki_URL)
html_MP <- html_table(html_nodes(html_Parliament, ".wikitable")[[tableNum]], fill=TRUE)
return(html_MP)
}
################################# FXN 2 ##########################
fxn_getRowNum <- function(dframe){
match_Region <- dframe[grepl("Region", dframe$X1),]
region_num <- as.numeric(rownames(match_Region))
reg_num <- list(match_Region, region_num)
return(reg_num)
}
################################### FXN 3 ########################
fxn_cleanRegName <- function(dframe){
regionNames <- dframe$X1
regionNames <- gsub("\\-.+\\]","", regionNames)
regionNames <- gsub("Region","", regionNames)
# trim the spaces next to the names
regionNames <- trimws(regionNames, "right")
return(regionNames)
}
################################# FXN 4 #########################
fxn_createDframes <- function(number, regNames){
allRegions <- replicate(number,
data.frame(Constituency=factor(),
`Elected MP`=factor(),
`Elected Party`=factor(),
Majority=numeric(),
`Previous MP`=factor(),
`Previous Party`=factor(),
stringsAsFactors=FALSE), simplify=FALSE)
names(allRegions) <- paste0("dframe", regNames[seq(0:9)])
return(allRegions)
}
#################### FXN 5 Create a Region column #####
fxn_createRegion <- function(dframeName){
# extract the region's name
col_Region <- dframeName[1,1]
col_Region <- gsub("\\-.+\\]", "", col_Region)
col_Region <- gsub("Region", "", col_Region)
col_Region <- trimws(col_Region, "right")
dframeName$Region <- col_Region
return(dframeName)
}
############################# FXN 6 ##########################
fxn_cleanDframeFinal <- function(dframeName){
trRegions <- dframeName %>%
filter(!str_detect(X1, ".+Region")) %>%
filter(!str_detect(X1, "^Constituency"))
# remove fourth column
if(length(names(dframeName)) > 7){
trRegions <- trRegions[, -c(4,7)]
}else{
trRegions <- trRegions[, -4]
}
trRegions <- data.frame(lapply(trRegions, as.factor))
# assign column names
names(trRegions) <- c("Constituency", "Elected MP",
"Elected Party", "Previous MP",
"Previous Party", "Region")
# remove all descriptions associated with names
trRegions <- trRegions %>%
mutate(`Elected MP` = gsub("\\(.+\\)", "",
`Elected MP`),
`Previous MP` = gsub("\\(.+\\)", "",
`Previous MP`))
return(trRegions)
}
######################### MAIN FUNCTION #############################
dframe_MPResults <- function(year_URL, tbl_Num){
# SECTION 1: return dframe from Wikipedia url and table position
dframe_Html <- fxn_getURL(year_URL, tbl_Num)
# SECTION 2: return dframe of region names and their row numbers
regName_Num <- fxn_getRowNum(dframe_Html)
# get dframe of RegionNames only
match_Region <- regName_Num[[1]]
# get vector of row numbers with the Region names
regionnum <- regName_Num[[2]]
# SECTION 3: return cleaned regional names from SECTION 2
regionNames <- fxn_cleanRegName(match_Region)
# SECTION 4: return a list with 10 empty dataframes
allRegions <- fxn_createDframes(length(regionnum), regionNames)
# SECTION 5: populate all dframes in list from SECTION 4
for(i in 1:length(regionnum)){
if(i == 1){
raw_data = dframe_Html[[1]]
prevNum = regionnum[length(regionnum)]
currentNum = nrow(dframe_Html)
allRegions[[1]] = dframe_Html[prevNum:currentNum,]
}else{
prevNum <- regionnum[i-1]
currentNum <- regionnum[i]
allRegions[[i]] <- dframe_Html[prevNum:currentNum, ]
}
}
# SECTION 6: apply function fxn_createRegion to all dataframes in allRegions
for(i in 1:length(allRegions)){
allRegions[[i]] <- fxn_createRegion(allRegions[[i]])
}
# SECTION 7: combine dataframes in list to a single unit
allRegions <- bind_rows(allRegions)
# SECTION 8: perform final cleaning on dataframe
trReg <- fxn_cleanDframeFinal(allRegions)
# SECTION 9: return dataframe
return(trReg)
}What Next?
One might say this is a repetition of Episode 2: The 1992 Parliamentary Results. On the contrary, a lot has improved since then and I will walk you through the various functions and the changes that have occured.
Libraries
I made use of 3 libraries: rvest, dplyr & stringr. rvest was used to access the web links and convert the resultig object into a dataframe. dplyr so I make use of the functions: filter, arrange, group_by etc. Last but certainly not the least stringr, this package was particularly useful for string manipulation, regular expressions.
Before I move forward, I would like to say a very big thank you to Hadley Wickham. He is the maintainer of all these 3 libraries and I truly appreciate his contribution to the R community. I look forward to meet you (fingers crossed for Rstudio conf 2020).
fxn_getURL
fxn_getURL <- function(wiki_URL, tableNum){
# get data and convert into table
html_Parliament <- read_html(wiki_URL)
html_MP <- html_table(html_nodes(html_Parliament, ".wikitable")[[tableNum]],
fill=TRUE)
return(html_MP)
}The function above takes 2 arguments: a URL and a table number.
The URL is a Wikipedia page giving information about the Parliamentary elections. I have provided in the introductory session, the urls for Ghana’s parliamentary results from 1996 to 2016.
The next argument is the numerical position for the table. On the Wikipedia page, the data is stored in a very long table which is usually the second table on the page. But on the 2012 results page, the information is available in the 3rd table
In this case, the function html_nodes uses a CSS class: .wikitable to get the information from the table. html_table converts the result to a dataframe.
The image below shows what the function returns when fed with the 1996 web link

Output from fxn_getURL
fxn_getRowNum
fxn_getRowNum <- function(dframe){
match_Region <- dframe[grepl("Region", dframe$X1),]
region_num <- as.numeric(rownames(match_Region))
reg_num <- list(match_Region, region_num)
return(reg_num)
}Using the dataframe from fxn_getURL(), I used this function to get the rows which contain the names of the regions (all those rows have the word Regions in the first column) . The function also returns their row numbers.
Since return statement can output only 1 item at a time, these 2 outputs were put into a list and returned so one can use indexing to access which output you needed.
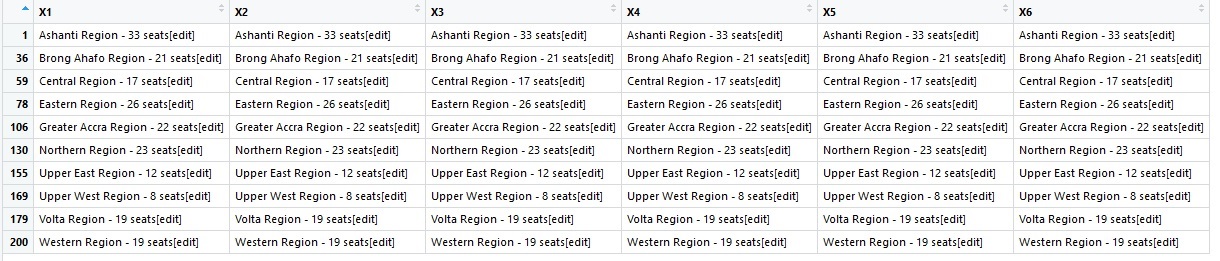
First element in list
The row numbers
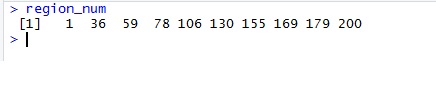
Second element in list
fxn_cleanRegName
fxn_cleanRegName <- function(dframe){
regionNames <- dframe$X1
regionNames <- gsub("\\-.+\\]","", regionNames)
regionNames <- gsub("Region","", regionNames)
# trim the spaces next to the names
regionNames <- trimws(regionNames, "right")
return(regionNames)
}fxn_cleanRegName() takes a dataframe with the Regional names;first element from the fxn_getRowNum as input and returns a “cleaned” version of the first column; a vector of the 10 regional columns.
Below is an image of the first column of the input.This is what it looks like before applying the function.
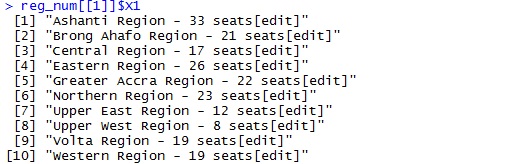
Details of reg_num before
So the function clears all text after from Region till the end and removes the white space. This is what it looks like after the function call

Region names after applying the function
fxn_createDframes
fxn_createDframes <- function(number, regNames){
allRegions <- replicate(number,
data.frame(Constituency=factor(),
`Elected MP`=factor(),
`Elected Party`=factor(),
Majority=numeric(),
`Previous MP`=factor(),
`Previous Party`=factor(),
stringsAsFactors=FALSE),
simplify=FALSE)
names(allRegions) <- paste0("dframe", regNames[seq(0:9)])
return(allRegions)
}There are 2 major things going on here;
- Creates a number of dataframes based on the number of regions using region_num. Each dataframe has 6 columns and they are all stored in a list; allRegions.
- Assign as names of the dataframes: “dframe” + regionNames.
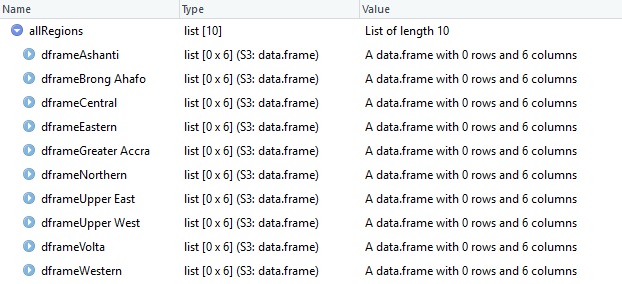
Contents of allRegions
Populating the dataframes
for(i in 1:length(regionnum)){
if(i == 1){
raw_data = dframe_Html[[1]]
prevNum = regionnum[length(regionnum)]
currentNum = nrow(dframe_Html)
allRegions[[1]] = dframe_Html[prevNum:currentNum,]
}else{
prevNum <- regionnum[i-1]
currentNum <- regionnum[i]
allRegions[[i]] <- dframe_Html[prevNum:currentNum, ]
}
}What I know believe to be the most important section is done here. The logic behind this code is to get the rows between 2 regional headings. This was the reason why I kept the row numbers; region_num. So all columns between 1 & 36 will be assigned to a dataframe, 36 & 59 to another dataframe,…. till 179 to 200.
- Run this loop 10 times; length of region_num
- If it was the first iteration, get the first dataframe in the list
- The starting index should be the final value in the region_num.
- The end index should be the length of the dataframe from fxn_getURL()

Contents of the first dataframe
fxn_createRegion
fxn_createRegion <- function(dframeName){
# extract the region's name
col_Region <- dframeName[1,1]
col_Region <- gsub("\\-.+\\]", "", col_Region)
col_Region <- gsub("Region", "", col_Region)
col_Region <- trimws(col_Region, "right")
dframeName$Region <- col_Region
return(dframeName)
}Each data frame is supposed to be a collection of results for a particular region. Hence using data from the first column, a new column Region is created. The logic above is implemented in fxn_createRegion
Applying fxn_createRegion
for(i in 1:length(allRegions)){
allRegions[[i]] <- fxn_createRegion(allRegions[[i]])
}Using a loop, I applied the function fxn_createRegion to all the dataframes in allRegions. The image below is the values of the Region column from the first, third and tenth dataframes.

Values of Region column from selected dataframes
Combine dataframes into a single unit
# combine all dataframe in allRegions
allRegions <- bind_rows(allRegions)The data in theindividual dataframes are fairly cleaned up so I combined then using the bind_rows() function from the dplyr package. The resulting dataframe is re-assigned to the same variable allRegions.

Class and the dimensions of allRegions
Final Data Cleaning and Shaping
fxn_cleanDframeFinal <- function(dframeName){
trRegions <- dframeName %>%
filter(!str_detect(X1, ".+Region")) %>%
filter(!str_detect(X1, "^Constituency"))
# remove fourth column
if(length(names(dframeName)) > 7){
trRegions <- trRegions[, -c(4,7)]
}else{
trRegions <- trRegions[, -4]
}
trRegions <- data.frame(lapply(trRegions, as.factor))
# assign column names
names(trRegions) <- c("Constituency", "Elected MP", "Elected Party",
"Previous MP","Previous Party", "Region")
# remove all descriptions associated with names
trRegions <- trRegions %>%
mutate(`Elected MP` = gsub("\\(.+\\)", "", `Elected MP`),
`Elected MP` = gsub("\\[.+\\]", "", `Elected MP`),
`Previous MP` = gsub("\\(.+\\)", "", `Previous MP`),
`Previous MP` = gsub("\\[.+\\]", "", `Previous MP`))
return(trRegions)
}trReg <- fxn_cleanDframeFinal(allRegions)
The final function does quite a number of things, so step-by-step, let’s go:
- Using str_detect(), remove all rows with the word Region, these were helpful in extracting the rows of values for each region.
- Also remove the rows with beginning with Constituency, they are duplicated column names, which we have already assigned in the fxn_cleanDframeFinal()
- The dataframe should have 7 columns out of which the fourth column, Majority this columns was supposed to be the number of votes for the Majority candidate.
- This was taken out since most of the rows did not have values.
- An if statement was put in place for 3 as some election years had 8 columns, the 4th and 7th columns did not have useful information hence were deleted.
- Using lapply(), all the columns were converted into factors.
- The dataframe was assigned new column names.
- Some members had their positions such as Minority Leader, Majority Leader etc in addition to their names. I did not conside them as useful information hence used gsub() to remove them.
Scraping data for 1996 till 2016 Parliamentary Results
mp_1996 <- dframe_MPResults("https://en.wikipedia.org/wiki/MPs_elected_in_the_Ghanaian_parliamentary_election,_1996", 2)
mp_2000 <- dframe_MPResults("https://en.wikipedia.org/wiki/MPs_elected_in_the_Ghanaian_parliamentary_election,_2000", 2)
mp_2004 <- dframe_MPResults("https://en.wikipedia.org/wiki/MPs_elected_in_the_Ghanaian_parliamentary_election,_2004", 2)
mp_2008 <- dframe_MPResults("https://en.wikipedia.org/wiki/MPs_elected_in_the_Ghanaian_parliamentary_election,_2008", 2)
mp_2012 <- dframe_MPResults("https://en.wikipedia.org/wiki/MPs_elected_in_the_Ghanaian_parliamentary_election,_2012", 3)
mp_2016 <- dframe_MPResults("https://en.wikipedia.org/wiki/MPs_elected_in_the_Ghanaian_parliamentary_election,_2016", 2)The final datasets are available here: 1996, 2000, 2004, 2008, 2012, 2016
I am so excited about my progress and I cannot wait to share another post.

